SIMD,向量机与自动向量化
并行化的需求
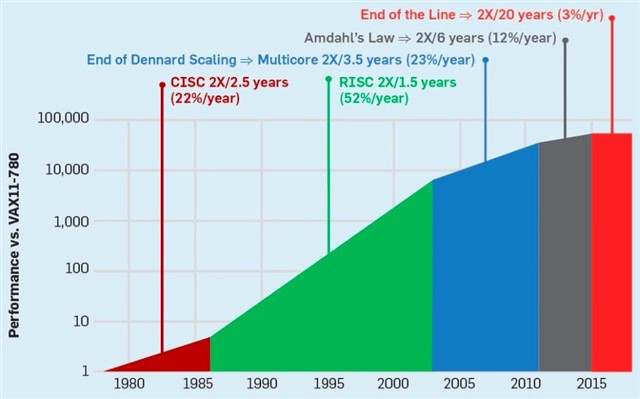
Moore 定律的终结
集成电路上可容纳的晶体管数目,约每隔两年便会增加一倍。曾经我们可以非常简单地提高单核的性能来提高计算机的运行效率,然而,现在这一美好的想法已经结束了。由于功耗墙的存在,如今,CPU单核性能已经很难提升,CPU频率已经早已脱离早期指数性发展曲线。
并行化
提高计算机性能的方法,是并行化。让多个CPU,多个核心并行地处理问题,是提高性能的最佳方法。目前,几乎所有的超级计算机都以多核、并行、相关的方向入手,进行性能调优。
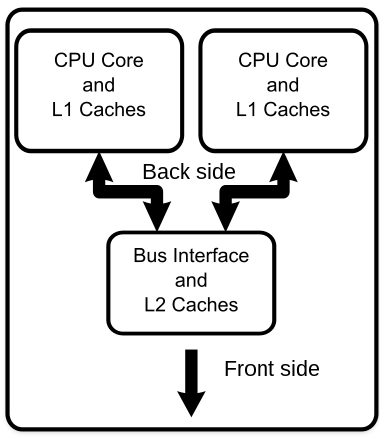
并行的手段
GPGPU - 异构计算
显卡(GPU)包含大量的核心来支持高度并行化的计算,最开始的在显卡上的编程是很困难的,随着时代的发展显卡的计算能力越来越不容小觑。通用计算显卡(GPGPU)也开始包含在编译优化的领域。AI模型在大型服务器集群上完成训练,要想投入实践就必须要把他编译到真正的体系结构上运行。
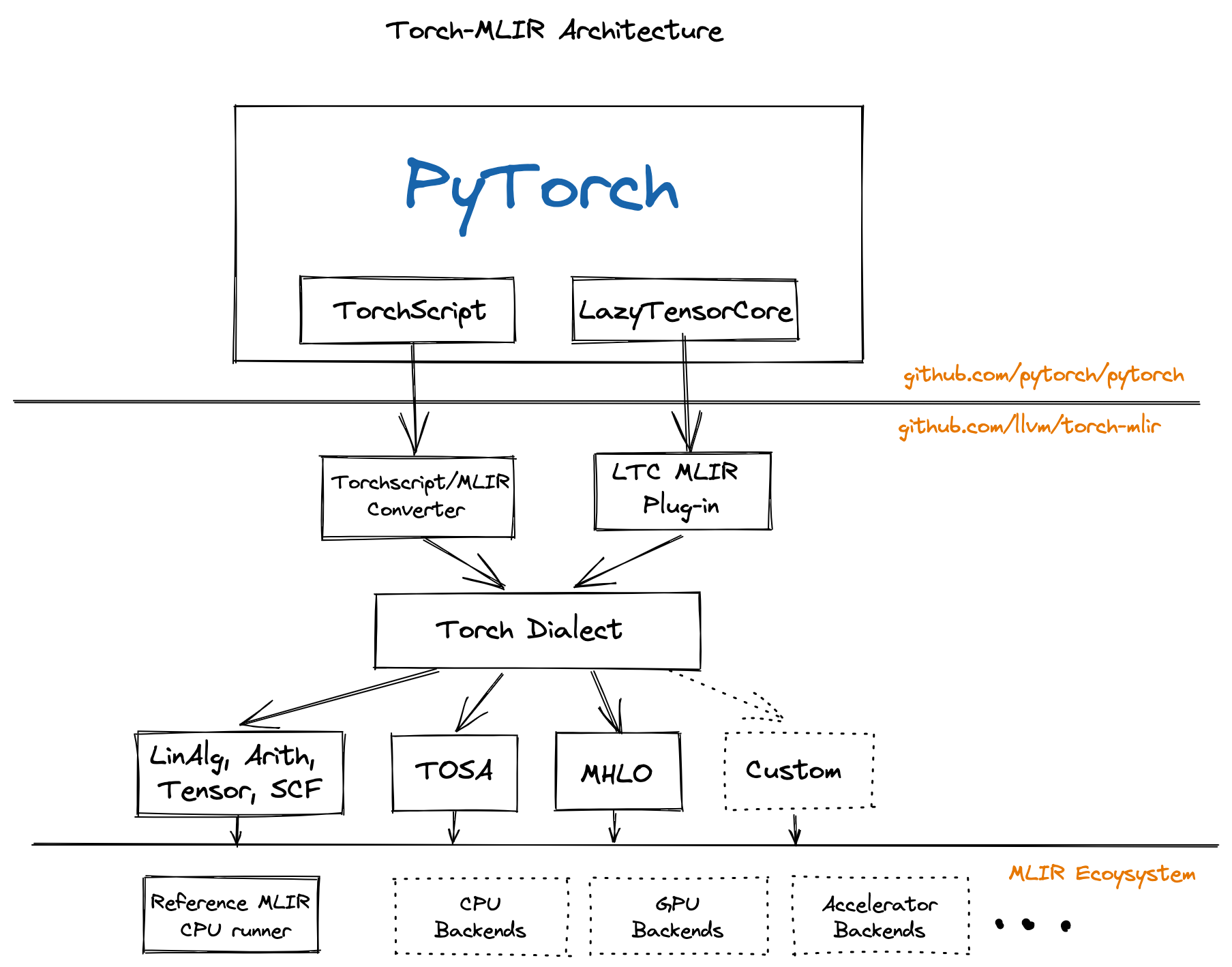
异构计算最复杂的问题在于,多个层面的IR包含可能的信息丢失,如何把IR紧密结合在一起,并完成相应的编译优化?
例如,你容易知道一个矩阵求两次转置恒等 \(\left(A^T\right)^T = A\) ,但如果矩阵转置已经被下降(lowering)到三地址码,甚至是更底层的指令,我们就丢失了矩阵实际上“求了两次转置”这么简单的优化条件。
MLIR的出现有助于解决这个问题,但不是这篇文章的重点,可能我会在后续的文章里写相关问题。
多核
为了实现并行化,我们可以给一个计算机加入多个核心。多核心的特点在于:
他们拥有不同的寄存器
有不同的中断处理请求
一般由操作系统-对称多处理(SMP)调度
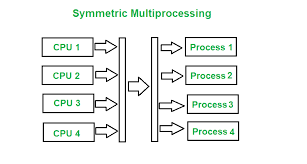
不同的寄存器代表每个核心具有不同的状态。例如,他们可能拥有不同的PC指针指向不同的代码区段,这样便可同时执行编写好的多段代码。
单核
乱序执行 (OoOE)
乱序执行(Out-of-Order Execution)是现代CPU最基本的一个并行手段。
1 | int test(int &a, |
这段 C++ 代码被编译为如下所示的汇编。
1 | lw a1, 0(a1) |
SIMD
OoOE在编程上由编译器全局指令调度器(Instruction Scheduler)优化。
单指令流多数据流(Single instruction, multiple data (SIMD)),提供了一种让我 们更好地进行向量计算的方式。
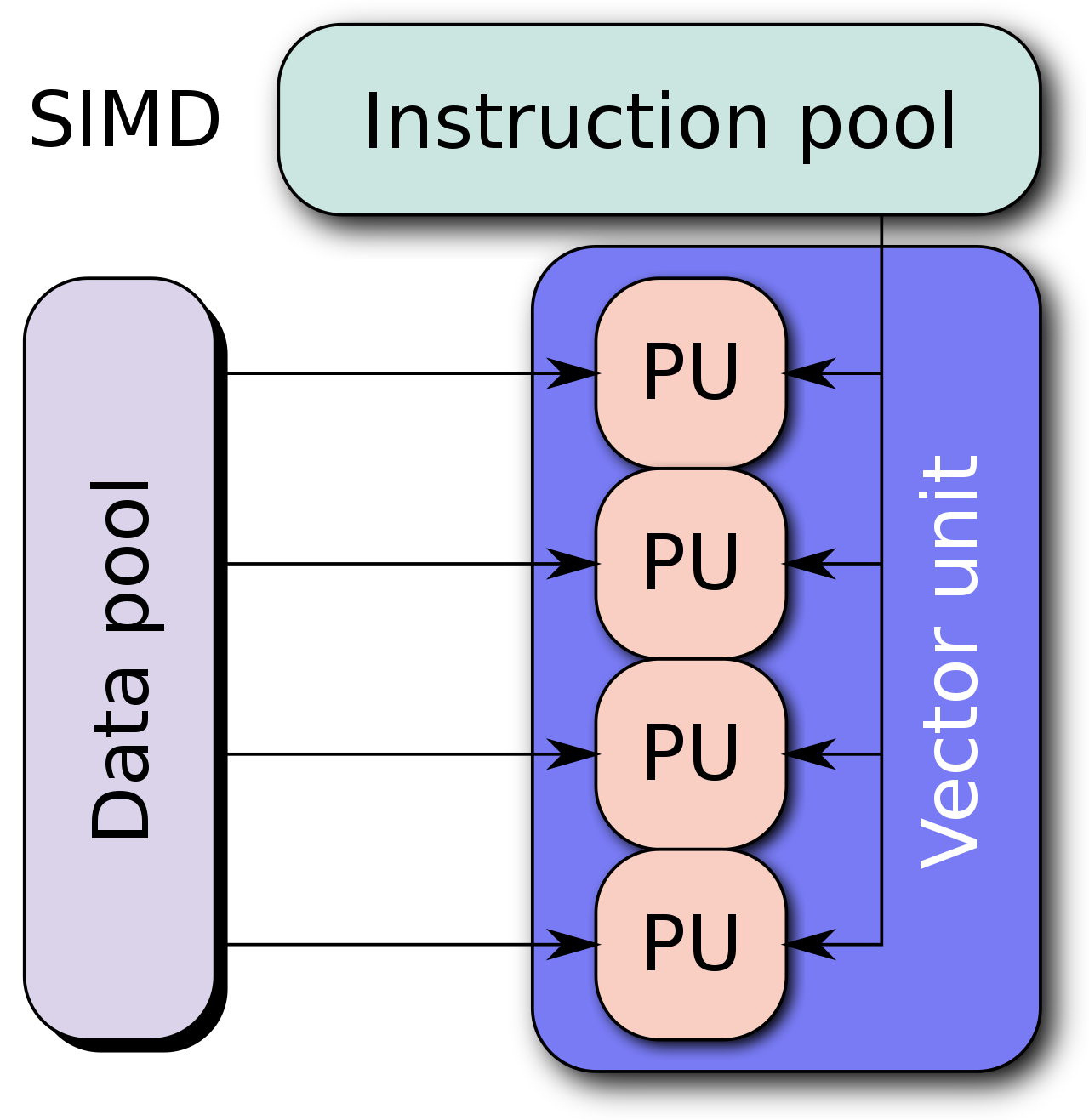
SIMD 的好处
通常情况下我们很难将串行代码转化为并行,为了设计并行算法通常需要改变原有的逻辑。

如图所示,在图形学中我们经常需要计算图像的颜色信息,而颜色在RGBA几个维度下的计算是可以向量化的。
SIMD 的缺陷
RISC-V Designers SIMD Instructions considered harmful. -- David Patterson
一开始,SIMD被认为是实现并行化简单有效的方法。我们将64位寄存器和ALU划分为许多8, 16, 32位的块,然后并行地计算它们。用每条指令的操作码(opcode)提供数据宽度和操作。
指令集膨胀
IA-32指令集已经从最开始的80多条指令增长到了现在的1400多条。SSE, AVX, 各种SIMD扩展和宽寄存器让指令集变得越来越复杂。
尾循环
SIMD 指令通常要求把数据完全加载到向量寄存器中,然后一次处理 \(n\) 个数据。但不是所有的应用场合,需要处理的数据都能被 \(n\) 整除,这就导致需要一个标量循环,完成向量循环的收尾工作,这个循环就被称为 尾循环。
Vector vs SIMD
向量机与SIMD的真正区别在于,向量长度是否在机器码层面确定。
1 | void *memcpy_vec(void *dst, void *src, size_t n) { |
这个代码展示了 RISC-V 实现memcpy的矢量版本(“伪汇编”,用C表示)。 这个程序最关键的部分在于vl的设定,每次循环都加载vl个元素,而vl对于 RISC-V 而言是一个每次循环可变的量。
CPU可以自己适配要计算多少个元素,给出尽量多的一次计算的元素,然后再一起操作。
vl 对于这段代码而言,是 “长度无关的”。对于传统的 SIMD 指令,我们需要用不同的指令,代表不同的向量长度,例如 SSE 通常加载 128 位,而 AVX2 通常加载 256 位。
这样做可以带来很多好处。首先,二进制程序便在支持不同矢量长度的 CPU 之间可以直接执行,而不需要重新编译(二进制兼容)。其次,SIMD 指令集通常需要内存对齐,尾循环等等不能很好向量化的部分,而可变向量长度 vl 的存在使得可以消除尾循环。
自动向量化(Auto-Vectorization)
可行性与好处
标量代码可以被自动向量化成含向量计算的代码。
事实上,大量的标量循环都可以被向量化 1
2
3
4
5void add(int * restrict A, int * restrict B, int n){
for(int i = 0;i < n;i++){
A[i] += B[i];
}
}
合法性
数据依赖 & Overlap (Alias Analysis)
1 | for (int i = 0; i < N; i += 1) { |
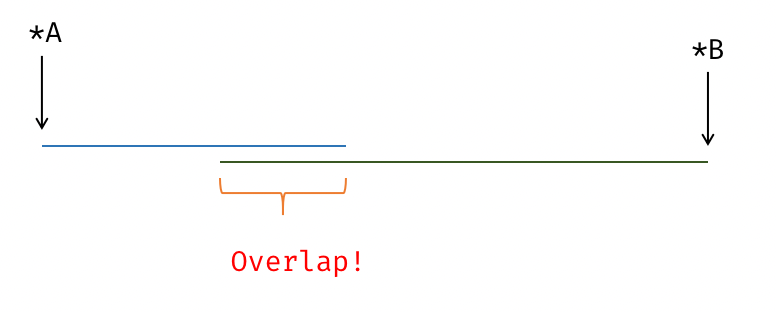
1 | for(int i = 1;i < n;i++) |
收益
必然导致的程序大小增加 / 标量循环和向量循环的选择和跳转
数据对齐的代价,尾循环的代价,都是需要考虑的因素。
1 | load i64; |
1 | load <4 x i64>; |
这个部分的代价计算在LLVM后端作为虚函数,由具体的Target给出估计。每个体系结构可能有不同的 SIMD 指令代价,但代价模型在优化层次是通用的
Transformation
下图展示了 LLVM Developer 2013 中,来自 Apple 的工程师给出的 LLVM 循环向量化工具。
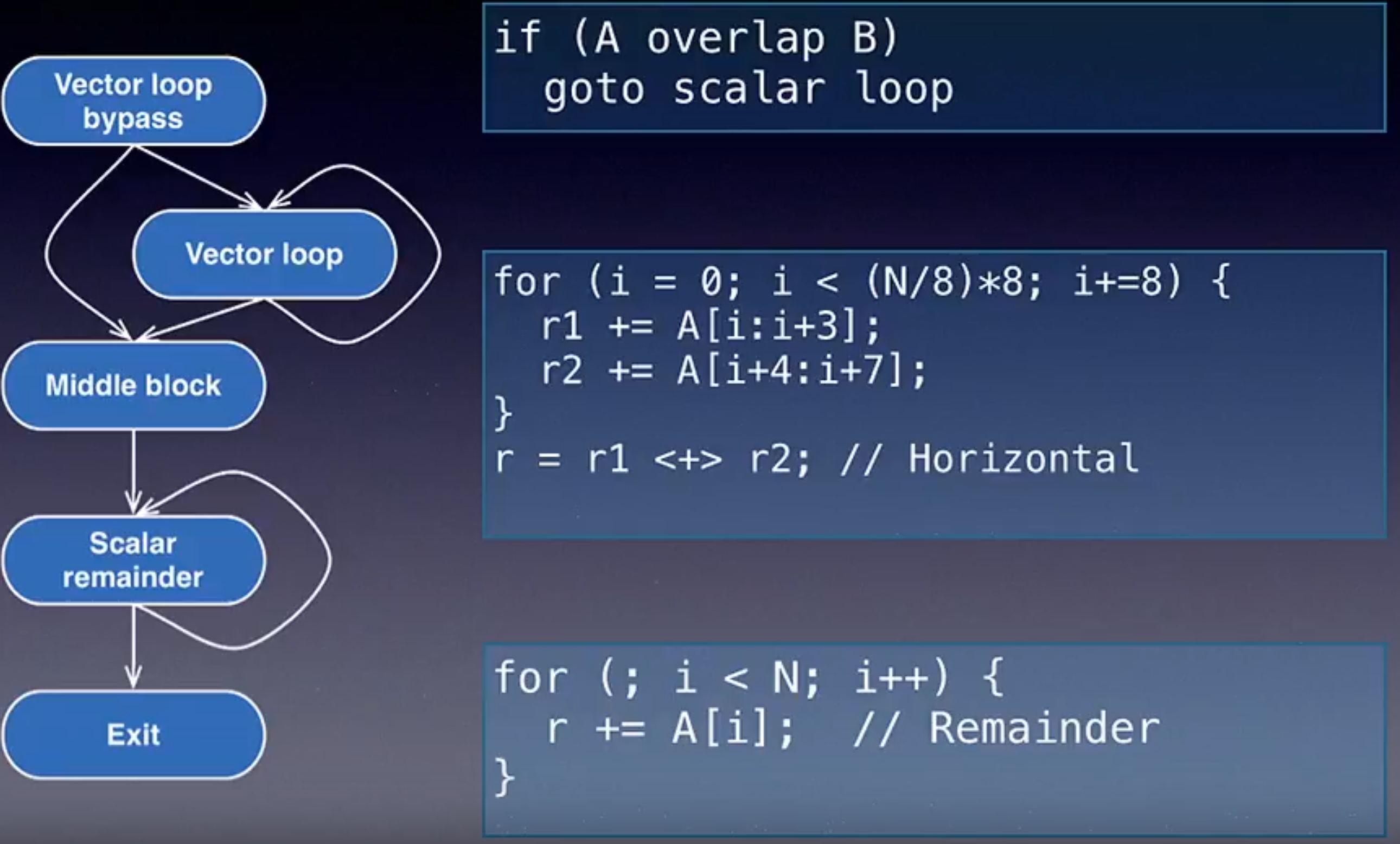
Loop Vectorizer Enhancements
现代化向量指令集可以更好地完成向量长度选择。
1 | memcpy: |
Mask & Predication
Predication (判定寄存器) 其实是来源于ARM SVE的一个东西
VP-based Loop Vectorizer 在 LLVM 中还没实现...