实用小指令
收集一些不错的偷懒指令
回到 git 根目录:
1 | cd `git rev-parse --show-toplevel` |
开一个临时目录,cd 过去
1 | cd `mktemp -d` |
cd 到刚刚创建的目录
1 | cd $_ |
推送当前分支
1 | git push -u github `git branch --show-current` |
回到 git 根目录:
1 | cd `git rev-parse --show-toplevel` |
开一个临时目录,cd 过去
1 | cd `mktemp -d` |
cd 到刚刚创建的目录
1 | cd $_ |
推送当前分支
1 | git push -u github `git branch --show-current` |
集成电路上可容纳的晶体管数目,约每隔两年便会增加一倍。曾经我们可以非常简单地提高单核的性能来提高计算机的运行效率,然而,现在这一美好的想法已经结束了。由于功耗墙的存在,如今,CPU单核性能已经很难提升,CPU频率已经早已脱离早期指数性发展曲线。
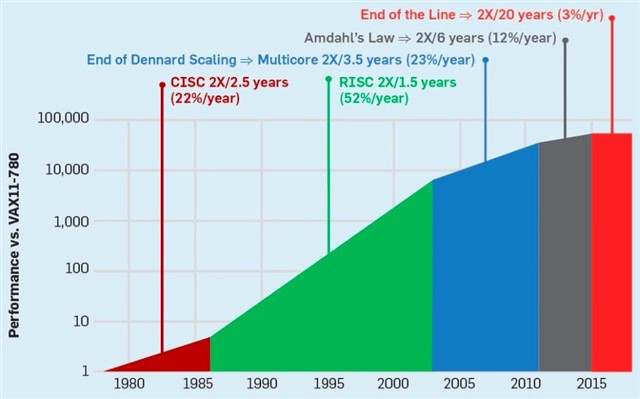
提高计算机性能的方法,是并行化。让多个CPU,多个核心并行地处理问题,是提高性能的最佳方法。目前,几乎所有的超级计算机都以多核、并行、相关的方向入手,进行性能调优。
显卡(GPU)包含大量的核心来支持高度并行化的计算,最开始的在显卡上的编程是很困难的,随着时代的发展显卡的计算能力越来越不容小觑。通用计算显卡(GPGPU)也开始包含在编译优化的领域。AI模型在大型服务器集群上完成训练,要想投入实践就必须要把他编译到真正的体系结构上运行。
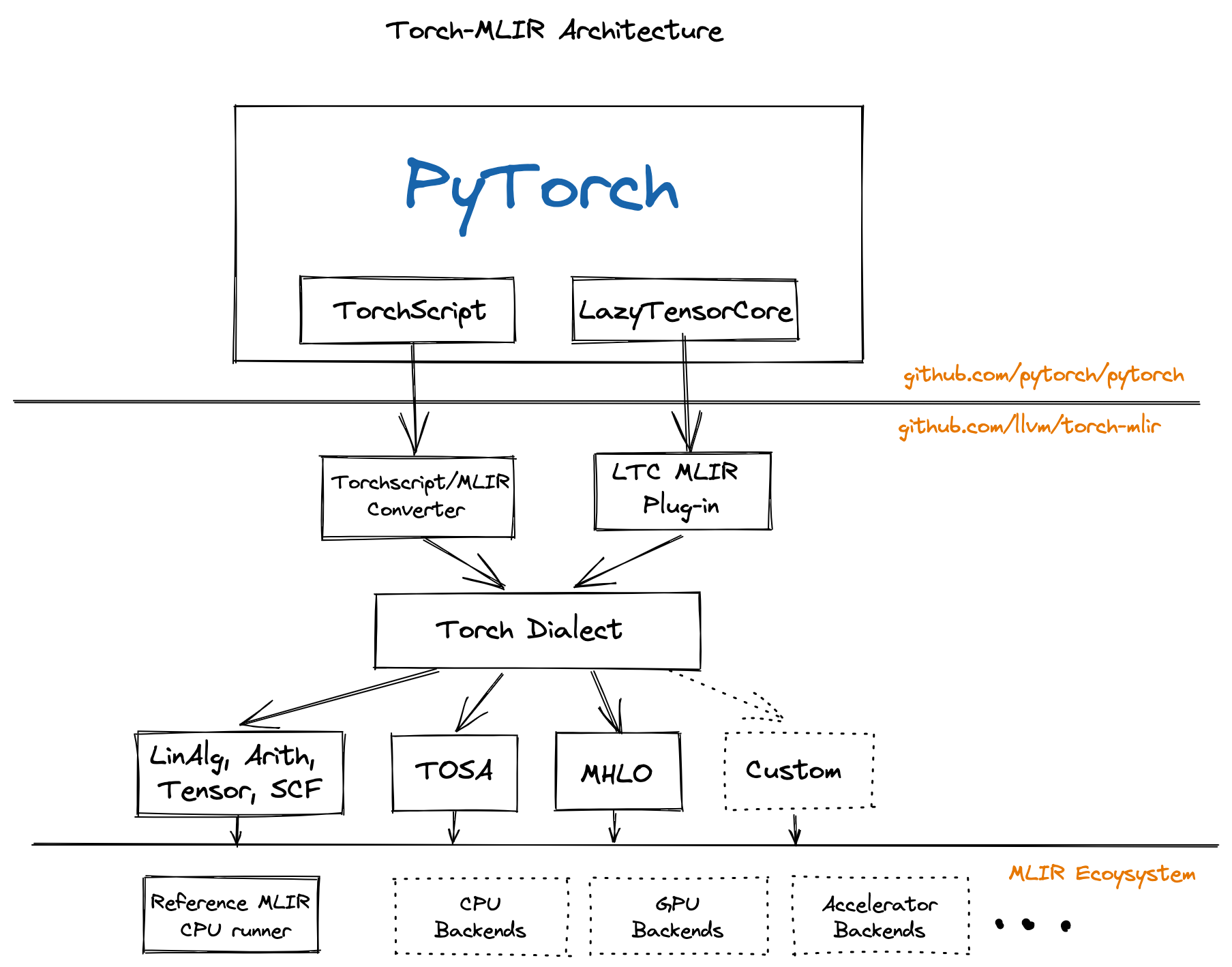
异构计算最复杂的问题在于,多个层面的IR包含可能的信息丢失,如何把IR紧密结合在一起,并完成相应的编译优化?
例如,你容易知道一个矩阵求两次转置恒等 \(\left(A^T\right)^T = A\) ,但如果矩阵转置已经被下降(lowering)到三地址码,甚至是更底层的指令,我们就丢失了矩阵实际上“求了两次转置”这么简单的优化条件。
MLIR的出现有助于解决这个问题,但不是这篇文章的重点,可能我会在后续的文章里写相关问题。
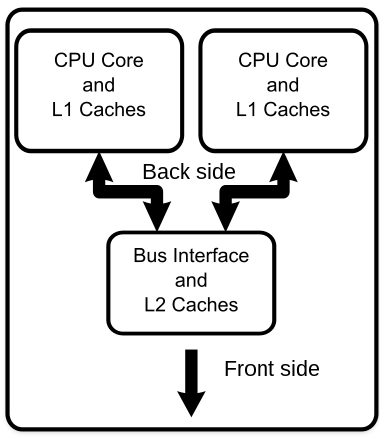
为了实现并行化,我们可以给一个计算机加入多个核心。多核心的特点在于:
他们拥有不同的寄存器
有不同的中断处理请求
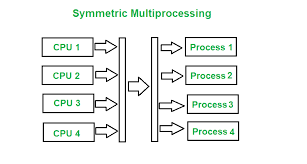
一般由操作系统-对称多处理(SMP)调度
不同的寄存器代表每个核心具有不同的状态。例如,他们可能拥有不同的PC指针指向不同的代码区段,这样便可同时执行编写好的多段代码。
乱序执行(Out-of-Order Execution)是现代CPU最基本的一个并行手段。
1 | int test(int &a, |
这段 C++ 代码被编译为如下所示的汇编。
1 | lw a1, 0(a1) |
OoOE在编程上由编译器全局指令调度器(Instruction Scheduler)优化。
单指令流多数据流(Single instruction, multiple data (SIMD)),提供了一种让我 们更好地进行向量计算的方式。
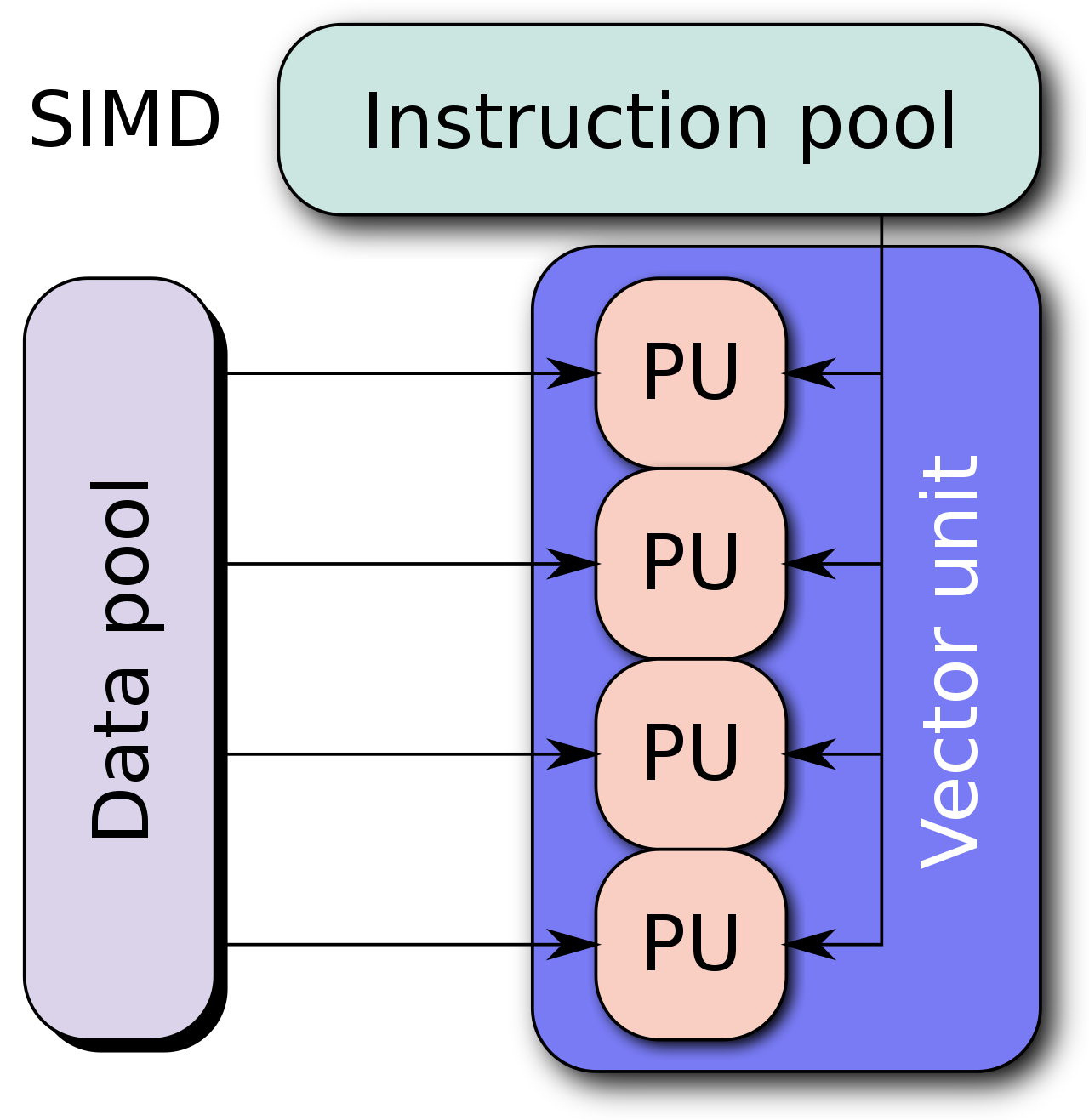
通常情况下我们很难将串行代码转化为并行,为了设计并行算法通常需要改变原有的逻辑。

如图所示,在图形学中我们经常需要计算图像的颜色信息,而颜色在RGBA几个维度下的计算是可以向量化的。
RISC-V Designers SIMD Instructions considered harmful. -- David Patterson
一开始,SIMD被认为是实现并行化简单有效的方法。我们将64位寄存器和ALU划分为许多8, 16, 32位的块,然后并行地计算它们。用每条指令的操作码(opcode)提供数据宽度和操作。
指令集膨胀
IA-32指令集已经从最开始的80多条指令增长到了现在的1400多条。SSE, AVX, 各种SIMD扩展和宽寄存器让指令集变得越来越复杂。
尾循环
SIMD 指令通常要求把数据完全加载到向量寄存器中,然后一次处理 \(n\) 个数据。但不是所有的应用场合,需要处理的数据都能被 \(n\) 整除,这就导致需要一个标量循环,完成向量循环的收尾工作,这个循环就被称为 尾循环。
向量机与SIMD的真正区别在于,向量长度是否在机器码层面确定。
1 | void *memcpy_vec(void *dst, void *src, size_t n) { |
这个代码展示了 RISC-V 实现memcpy的矢量版本(“伪汇编”,用C表示)。 这个程序最关键的部分在于vl的设定,每次循环都加载vl个元素,而vl对于 RISC-V 而言是一个每次循环可变的量。
CPU可以自己适配要计算多少个元素,给出尽量多的一次计算的元素,然后再一起操作。
vl 对于这段代码而言,是 “长度无关的”。对于传统的 SIMD 指令,我们需要用不同的指令,代表不同的向量长度,例如 SSE 通常加载 128 位,而 AVX2 通常加载 256 位。
这样做可以带来很多好处。首先,二进制程序便在支持不同矢量长度的 CPU 之间可以直接执行,而不需要重新编译(二进制兼容)。其次,SIMD 指令集通常需要内存对齐,尾循环等等不能很好向量化的部分,而可变向量长度 vl 的存在使得可以消除尾循环。
标量代码可以被自动向量化成含向量计算的代码。
事实上,大量的标量循环都可以被向量化 1
2
3
4
5void add(int * restrict A, int * restrict B, int n){
for(int i = 0;i < n;i++){
A[i] += B[i];
}
}
数据依赖 & Overlap (Alias Analysis)
1 | for (int i = 0; i < N; i += 1) { |
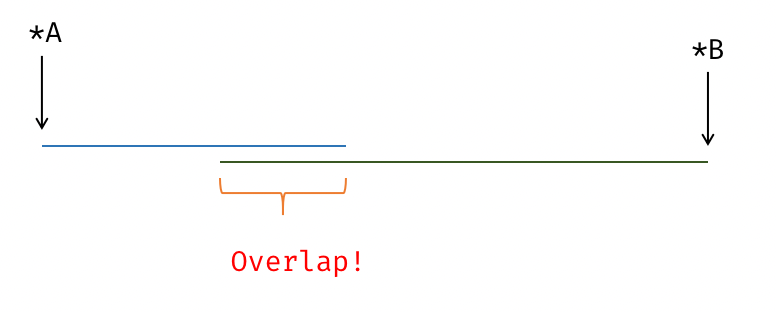
1 | for(int i = 1;i < n;i++) |
必然导致的程序大小增加 / 标量循环和向量循环的选择和跳转
数据对齐的代价,尾循环的代价,都是需要考虑的因素。
1 | load i64; |
1 | load <4 x i64>; |
这个部分的代价计算在LLVM后端作为虚函数,由具体的Target给出估计。每个体系结构可能有不同的 SIMD 指令代价,但代价模型在优化层次是通用的
下图展示了 LLVM Developer 2013 中,来自 Apple 的工程师给出的 LLVM 循环向量化工具。
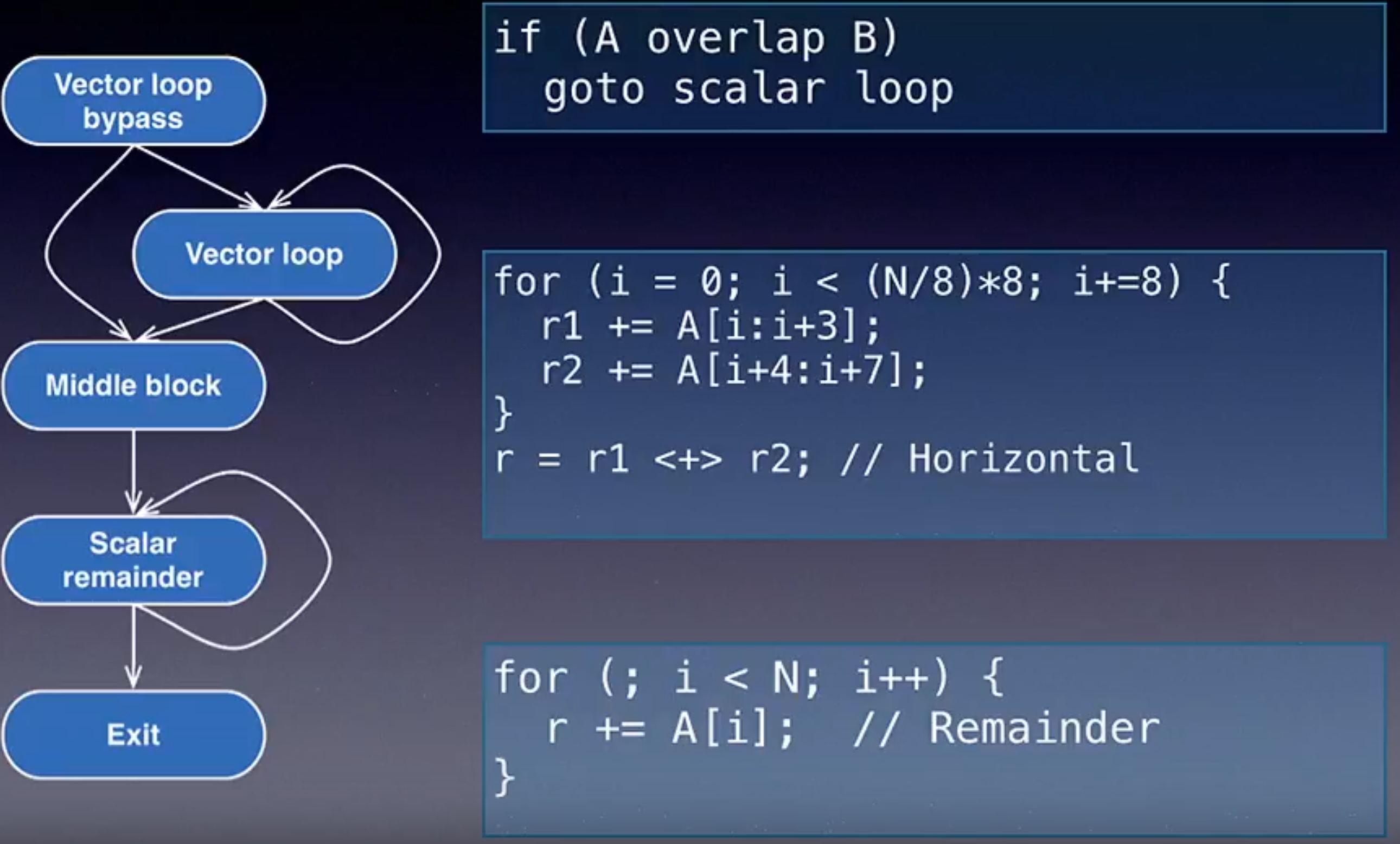
现代化向量指令集可以更好地完成向量长度选择。
1 | memcpy: |
Predication (判定寄存器) 其实是来源于ARM SVE的一个东西
VP-based Loop Vectorizer 在 LLVM 中还没实现...
每次开机或重启后,新开一个终端,总会有漫长的conda加载时间。
conda init 会在你的shell中写入 conda initialize 相关的内容,保证 conda 环境被初始化。
1 | # >>> conda initialize >>> |
然而,不知道为什么,这个东西会严重拖慢第一次打开终端时进入正常交互式shell的速度。
在这里我的解决方案是,添加一个延迟加载选项。我的日常环境中不是所有的终端都会用上conda,甚至大概率不用。所以按需要加载环境就非常重要。
或许可以设计一个load_conda的函数,然后需要用conda的时候加载它!
然而,这样好像太蠢了!有没有一个办法能够在我输入conda指令时,虽然引发了一个错误但自动加载conda环境,然后执行加载后的conda? (类似于虚拟内存与缺页中断)
我把激活conda相关的变量改成了这样:
1 | # https://www.reddit.com/r/zsh/comments/qmd25q/lazy_loading_conda/ |
这个方案实在是太巧了!很符合我对未来的想象(
当你在shell输入conda时,没有加载conda时会触发load_conda,然后自动加载conda。之后又会被alias到conda指令本身,看起来就像无缝加载了一个变量一样!
系统调用syscall可以看作一次特殊的函数调用。程序按照Calling Convention将参数放在寄存器、堆栈中,然后CPU硬件修改程序计数器,权限状态等信息,跳转到内核提前设定好的一个位置(stvec)。
之后,处理器开始执行内核代码。内核代码执行完后,恢复发生中断时的现场,继续运行程序。
这个lab一共有两个实验,分别是trace和sysinfo,前者要求我们在之后系统调用时,打印系统调用的情况,后者需要我们提供内存使用和进程的使用信息。
我的所有实验代码都可以在github找到。
这个实验重点是对于每个proc结构体保存一个flag,表示他要不要进行trace。
然后,在系统调用返回时,设计成可以打印结果:
1 | num = p->trapframe->a7; |
tsysflag是需要新写到结构体里的一个成员。
syscallnames,每个系统调用的字符串名字。
1 | static char *syscallnames[] = { |
trace实验的所有代码参考这里。
主要是实现两个模块,进程和内存。
内存方面,内核用一个kfreelist来保存现在空闲的内存信息,这是一个链表,统计时只需要遍历链表即可。内存都是按照页分配的,所以结果就是PGSIZE * free_num。
1 | // kernel/kalloc.c |
进程计数,直接遍历进程数组,看他们中哪些不是UNUSED。
1 | // kernel/proc.c |
最后,整理出系统调用的结果,把他们拷贝到用户态去。
1 | // kernel/sysinfo.c |
这个实验要求设计一个素数发生器。基于管道实现埃氏筛。
1 |
|
最开始的实验版本我在fork之后才调用pipe,导致出现了逻辑上的问题。这个程序中如果不及时关闭pipe中不需要的那个fd,会导致阻塞/资源用尽。
继续Lab1的实验,这个程序要求我们用一个管道实现父子进程通信,即开一个pipe,然后父进程发一个ping,子进程表示自己收到了ping,然后再翻过来。
1 |
|
我的实验环境是一台PC, 运行在我的寝室,作为工作站运行。
1 | [I] lyc@lyc-workstation ~/w/学/C/c/MIT6.S081 (master)> neofetch |
要运行老师给的xv6操作系统代码,必须先有交叉编译工具。[1]
用gentoo的crossdev工具[2]安装跨指令集的编译工具,包括GNU binutils, gcc, g++。
1 | sudo crossdev --stable -t riscv64-unknown-linux-gnu |
安装打开了riscv64对应的编译开关的qemu,我的实验主机是Gentoo Linux操作系统,在Portage中加入USE
1 | write-use app-emulation qemu qemu_user_targets_riscv64 qemu_softmmu_targets_riscv64 |
其中write-use是一个自己写的辅助脚本
1 | lyc@lyc-workstation ~> cat $(which write-use) |
然后,重新编译qemu
1 | sudo emerge -av qemu |
1 | git clone git://g.csail.mit.edu/xv6-labs-2021 |
1 | cd xv6-labs-2021 && git checkout util |
1 | [I] lyc@lyc-workstation ~/w/学/C/c/M/xv6-labs-2021 (util)> make qemu |
Ctrl-a x退出系统。
实现一个UNIXsleep程序,要求使用sleep系统调用。
user/下有不少可以参考的程序kernel/sysproc.c中可见main函数应该使用exit(0)来正常推出Makefile的UPROGS中。1 | UPROGS=\ |
1 | // kernel/sysproc.c |
其中,这里的sleep函数是一个在proc.c中实现的函数
1 | // kernel/proc.c |
调度器、状态转移,这些概念应该在之后的课程中会涉及到。
1 | // user/sleep.c |
其中,他这里的uint还会出现一些编译错误
1 | In file included from user/sleep.c:1: |
我在user/user.h中加了一个类型定义,来解决这个编译错误
然后再次make qemu就可以了。